
ルーターアクセスログの長期保管について
とらくらのインフラエンジニア、takaiです。
コロナの影響で急遽リモートワーク用にVPN環境を整えた企業も多いと思います。
その際、気になるのが不正アクセスへの不安ではないでしょうか。
万が一不正アクセスを受けた場合、アラート検知をしたとしても対処対策が困難な場合があると思います。せめて通信ログだけでも保存できていれば、事後対処に役に立つ場合も少なからずあります。
そこで、ルーターの通信ログを長期的に保管する必要性が出てきます。
保管するログは基本的に万が一の際しか閲覧することがありませんので、オンプレで大容量のストレージを準備するのは運用管理面を考えても負担が大きく、不意の故障によりログを焼失するリスクもあり、RAID等それなりの構成を組むと費用的にも負担が増えてしまいます。
そのような時には、運用負荷を低減して安価に保存する方法として、AWSのS3バケットに保存する方法があります。
AWS S3
S3バケットは、データの保存容量に応じてデータ取り出し時に料金がかかりますが、データ追加時には料金は発生しません。
データ保存容量に対する金額についても、下記料金表を参照いただくと、通常の[S3標準]でも EC2 と比べるとかなり安価な設定となっており、オンプレでハードウェアの保守メンテナンス及び対応工数を考慮しても安価だと思います。
1年、2年と長期で保管する場合、古いデータほど取り出す可能性は低くなりますので、保管先を[S3 Standard]や[S3 Glacier]などに順次移行することでコストを抑えることができます。
https://aws.amazon.com/jp/s3/pricing/
作業内容
企業向けルーターはSYSLOG転送機能を有している場合が多いので、社内に構築したSYSLOGサーバーを経由してS3へログを転送することで対応するようにします。
必要な設定は下記の通り、通信障害などでのログ消失を防止する為、SYSLOGサーバーはAWS上ではなく、社内にオンプレ構築とします。
■オンプレ側
①社内SYSLOGサーバー構築
②ルーターから社内SYSLOGサーバーへの転送設定
③SYSLOGサーバーに AWS CLI をインストール
■AWS側
④S3バケットの作成
⑤IAMアカウントの作成
■オンプレ側
⑥crontabで受信したSYSLOGをS3へ定期的にsync (sync時にS3側の削除は行わない)
■AWS側
⑦S3バケットのライフサイクルポリシーを設定
社内のSYSLOGサーバーでのログ保管は10日~30日程度に抑えて、それ以降はS3での保管としますので、ラズパイなどでも問題ないと思いますが、ラズパイの場合はmicroSDのRW寿命の関係からSYSLOGの保存先用に別途HDD等を指定した方が良いでしょう。
S3のバケットでライフサイクルポリシーを利用して、ログの保存期間を90日等残したい期間を設定します。
年単位でログを残しておく場合は、半年等一定期間経過したログについては、ライフサイクルポリシーを利用して、月単位でS3 Glacierなどへ移動させることでランニングコストを抑えることができます。
オンプレ側の準備
①SYSLOGサーバーの構築
今回はCentOS 7 を使用して構築しました。
ルーターからのSYSLOGを受信できるようにするため、rsyslogの設定を変更するため、/etc/rsyslog.confを編集します。
まず、su – して root になっておくか、各コマンド実行時に sudo してください。
ポート514でsyslogの受信を許可する為、下記定義の # を外します。
# Provides UDP syslog reception
#$ModLoad imudp
#$UDPServerRun 514
# Provides TCP syslog reception
#$ModLoad imtcp
#$InputTCPServerRun 514次に、送信元の機器単位でログを分割するように、下記定義を追記します。
$template ClinetLog,"/var/log/rsyslog/%fromhost%/%$year%%$month%%$day%_messages.log"
*.* -?ClinetLogこれで、受信したSYSLOGは[/var/log/rsyslog/送信元ホスト名]のフォルダ内に[年月日_messages.log]というファイル名で保存されます。
続いて /etc/logrotate.conf に下記を追記します。
dateformat .%Y%m%dここまで、設定を行ったらrsyslogのサービスを再起動します。
[root@logserver ~]# systemctl restart rsyslog②ルーターから社内SYSLOGサーバーへの転送設定
この段階でルーターにSYSLOG送信の設定を行い、[/var/log/rsyslog/送信元ホスト名]のフォルダ内にログが記録されていることを確認します。
ログが記録されていることが確認出来たら、ログローテートを行うため、[/etc/logrotate.d] に下記のような定義ファイルを作成します。
下記定義では、ログファイルは日で分割し、30日分を保存、ローテートした際にterで圧縮をしています。
/var/log/rstslog/gateway
{
daily
rotete 30
missingok
compress
sharedscripts
postrotate
/bin/kill -HUP `cat /var/run/syslogd.pid 2> /dev/null` 2> /dev/null || true
endscript
}③AWS CLIのインストール
AWS CLIを利用するには python3 が必要になるため、これをインストールします。
[root@logserver ~]# yum install python3pythonがインストールされたことを確認します。
[root@logserver ~]# python3 -V
Python 3.6.8
[root@logserver ~]# pip3 --version
pip 9.0.3 from /usr/lib/python3.6/site-packages (python 3.6)AWS CLIのインストールをします。
[root@logserver ~]# pip3 install awscliAWL CLIがインストールされたことを確認します。
[root@logserver ~]# aws --version
aws-cli/1.20.41 Python/3.6.8 Linux/3.10.0-1160.el7.x86_64 botocore/1.21.41これでオンプレ側での準備が終わりましたので、AWS側の準備を行います。
AWS側の準備
AWSでは、ログを保存する為のS3バケットの作成と、AWS CLIから接続する為のIAMアカウントの作成を行います。
④S3バケットの作成
S3の管理画面から「バケットの作成」をクリックします。
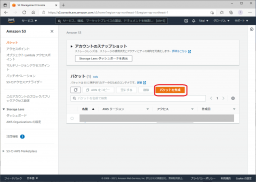
作成するバケット名を入力し、リージョンを東京とします。
バケット名は、AWSの標準パーテション内(リージョン単位ではありません)で一意になる必要があるため、他のユーザーが作成済みの名前は使えませんので注意が必要です。
概ね、AWS内で一意になる必要があると思っておけばよいでしょう。
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/userguide/bucketnamingrules.html
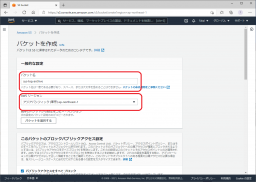
次に、パブリックアクセスの許可設定を行います。
外部に公開するべきデータではないので規定値のまま、パブリックアクセスは全てブロックします。
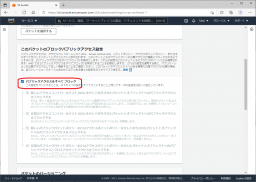
バケットのバージョニング(保存データの世代管理)は任意で設定を行います。
今回は、設定を有効にします。
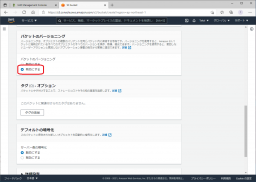
設定を確認して「バケットの作成」をクリックします。
バケットが作成されました。
⑤IAMアカウントの作成
作成したS3バケットへアクセスする為のIAMアカウントを作成します。
IAMの管理画面左ペインから[ユーザー]を選択し、[ユーザーを追加]をクリックします。
ユーザー名は、わかりやすく先ほど作成したS3バケットと同じ名称にします。
アクセス許可については、AWS CLIからのアクセス許可が必要になるだけですので、[アクセスキー・プロセスによるアクセス]のみチェックを入れて[次のステップ]をクリックします。
ユーザーを追加するグループを新規で作成する為、[グループの作成]をクリックします。
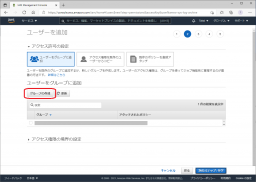
グループ名についても、S3バケットと同じ名称にします。
アクセス権については、[S3]でフィルタを行い[AmazonS3FullAccess]を選択、[グループの作成]をクリックします。
※要件に応じて適切な必要最小限の権限を割り当てるようにしてください。
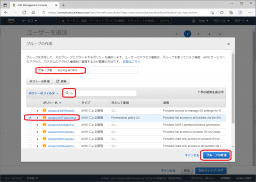
作成したグループが選択されていることを確認して、[次のステップ]をクリックします。
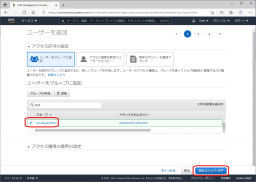
必要に応じてタグの設定を行い、[次のステップ]をクリックします。
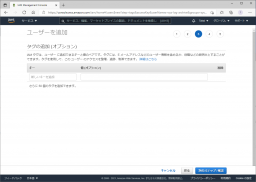
設定内容を確認して[ユーザーの作成]をクリックします。
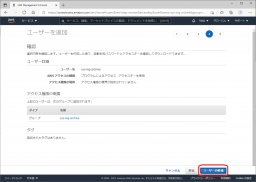
作成に成功すると、[アクセスキーID]と[シークレットアクセスキー]の確認ができますので、この情報を控えてください。
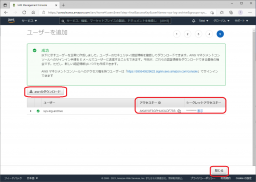
ユーザー画面に戻りますので、作成したユーザーが追加されていることを確認します。
AWS S3 への転送設定
⑥S3へ定期的にsyncさせる
AWS CLIに先ほど作成した接続用IAMアカウントの[アクセスキーID]と[シークレットアクセスキー]を設定します。
※東京リージョンは[ap-northeast-1]
[root@logserver ~]# aws configure
AWS Access Key ID [None]: xxxxxxxxxxxxxxxxxxxx
AWS Secret Access Key [None]: xxxxxxxxxxxxxxxxxxxx
Default region name [None]: ap-northeast-1
Default output format [None]: jsonIAMアカウントの[アクセスキーID]と[シークレットアクセスキー]が設定されたことを確認します。
[root@mrtg ~]# aws sts get-caller-identity
{
"UserId": "xxxxxxxxxxxxxxxxxxxx",
"Account": "xxxxxxxxxxxxxxxxxxxx",
"Arn": "arn:aws:iam::xxxxxxxxxxxxxxxxxxxx:user/logs"
}AWS CLIでS3へのアクセスを確認します。
[root@logserver ~]# aws s3 ls
2021-09-14 13:29:59 logs実際にログの転送を試します。
今回は /var/log/rstslogの中身を全て転送します。sync コマンドを使用することで更新されたファイルだけを転送するようにします。
[root@logserver ~]# aws s3 sync /var/log/rsyslog s3://logs/rsyslog/AWS側からログが転送されていることを確認します。
問題ないようであれば、crontabに設定を行い、cronを再起動します。
頻繁に同期する必要もないので、3時間おきに同期するように設定してみます。
[root@logserver ~]# crontab -e
5 */3 * * * /usr/local/bin/aws s3 sync /var/log/rsyslog s3://logs/rsyslog/ --content-type application/octed-stream > null
[root@logserver ~]# systemctl restart crond.serviceAWS S3バケットのライフサイクルポリシー設定
⑦ライフサイクルポリシーの設定
ログの転送ができるようになりましたので、S3バケット側のデータ保存期間設定を行います。
作成したバケットをクリックします。
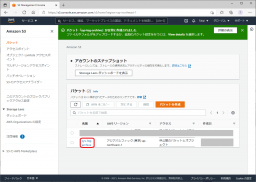
[管理]を開き、[ライフサイクルポリシー]項の[ライフサイクルルールを作成する]をクリックします。
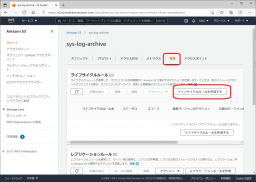
ライフサイクルルール名と適用範囲を設定します。
今回は、S3バケット全体に対して適用したいので、[ルールスコープ]は[すべてのオブジェクト]を対象にしています。
ルール名は設定内容がわかるようにしています。
今回は、古い世代は10日で削除、最新世代は90日で削除したいので、[10-90Delete]としています。
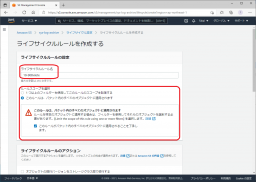
下にスクロールして、[ライフサイクルルールのアクション]を設定します。
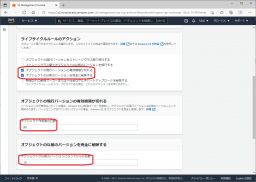
さらに下にスクロールして、[保存]をクリックします。
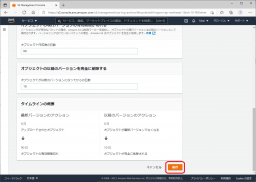
ライスサイクルが作成されたことを確認します。
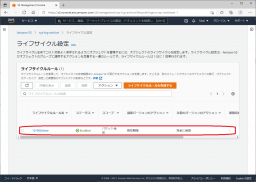
これで一通りの設定が完了しました。
運用を行い、想定通りのタイミングで削除されることを確認します。
最後に
今回は単純にログファイルをsyncしていますが、S3からの取り出しはアイテム単位で課金される形になるため、日単位などで複数のログファイルを1個のtarやzipに圧縮したものをS3に同期すると取り出す際の課金を抑えることができます。
最短でAWSを習得したい方におすすめ!
オンラインスクール「とらくら」
当ブログを運営しているオンラインスクール「とらくら」では、AWSを扱うために必要不可欠な主要サービスの知識を、理論学習だけでなく、環境構築をハンズオン形式で実践できるカリキュラムをご用意しています。
随時、個別の無料説明会を開催しており、講座内容や料金、本講座を受講するメリット・デメリットについてはもちろん、業界に精通しているからこそできるエンジニアのキャリアプランや業界の情勢などを、ざっくばらんにお話します。
些細なことでも、お気軽にご相談ください。


投稿者プロフィール

-
<インフラエンジニア>
■ 家電量販店での商品販売や配送、設置、テクニカル対応等の経験と知識を活用し、Windows環境を主としてオンプレミスの端末、サーバー、ネットワーク構築・運用経験豊富なエンジニア。
■ 広く浅くDIY、電子工作、車、カメラ、動画撮影など多岐色々なことに興味を持ち、自宅に簡易な検証環境を構築して日々コンピュータと戯れている逸般人
最新の投稿
 AWS2021年12月3日削除してしまったデフォルトVPCやサブネットを再作成する
AWS2021年12月3日削除してしまったデフォルトVPCやサブネットを再作成する AWS2021年10月13日AWS認定試験の受験(テストセンター版)
AWS2021年10月13日AWS認定試験の受験(テストセンター版) インフラ2021年9月28日ヤマハRTXを利用したVPN接続の利用状況を把握したい
インフラ2021年9月28日ヤマハRTXを利用したVPN接続の利用状況を把握したい AWS2021年9月16日ルーターアクセスログの長期保管について
AWS2021年9月16日ルーターアクセスログの長期保管について
